Binary Search Trees
Best thing about data structures is that you can have a structure or a container that can hold data and a set of methods (algorithms) that can operate on your data. Yeah, that’s pretty much the receipe of a data structure. Container of data + Operations on that container = Data structure
So we can have an array of elements and do a lot of things with that array like; sorting the data, finding an element in the array, adding or removing elements in that array. But when it comes to real world applications, we care about speed and efficiency. We want to do whatever we want with the data as fast as possible! An array wouldn’t provide the most efficient way in certain context. If we want to find an element in a huge array, we have to go through the entire array to look for it, so that’s O(N) time complexity. But what if there’s a faster way? A way to find an element without going through the entire array? A way to find the smallest element in the array for example? That’s where Binary Search Trees (or BSTs) step in.
Binary Search Tree is a dynamic data structure with a collection of nodes that follow a certain ordering property.
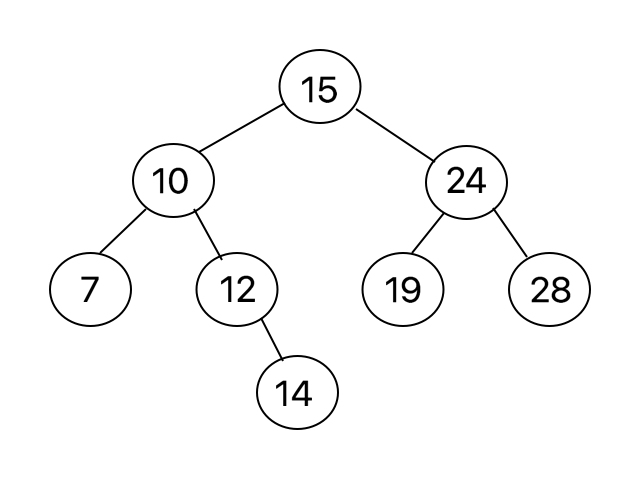
An example of a Binary Search Tree.
Properties of a BST
- Each tree has a root node.
- Each node has a reference of the left child and a reference of the right child.
- Each node can have up to 2 children (that's why its called binary).
- A node that doesn't have children is called a leaf node.
- Nodes are ordered in a way where key(left child) < key(root) < key(right child).
class TreeNode {
public:
TreeNode *left;
TreeNode *right;
int val;
TreeNode(int k) : val(k) {
left = NULL;
right = NULL;
};
};Since there is an ordering property in this tree, standard operations like Search/Insert/Delete are faster when used on a BST than on an array.
BSTs are useful when it comes to frequent queries, searching for a key in a BST provides lookup of time complexity O(h) where h is the height of the tree, and it is proved that h = log(N), faster than going through the array of elements in O(N). Cutting the search cost from O(N) to O(logN) is significant to applications that can only afford a logarithmic operation in that structure.
How can you know the number of nodes in a tree? Well, counting them is a strategy, but don’t do that. Please. Instead, think of the levels of the tree. First level which is the root node has one node. Second level has two nodes. Third level has four nodes. You see the pattern? Each level you go down the tree, the number of nodes increases by a multiple of 2 since each node can have two children. So if you have a a tree of height 12, you can get the number of nodes through this equation.
Number of nodes: n = 1 + 2 + 4 + 8 + ... + (2^h-1) = (2^h) - 1
Max # of nodes at height h: (2^h) - 1
Height of the tree: h = log(n+1)
This table is a small comparison of basic operations in
| Operation | Search() | Delete() | Insert() | Max()/Min() |
|---|---|---|---|---|
| Unsorted Array | O(N) | O(N) | O(N) | O(N) |
| Binary Search Tree | O(lgN) | O(lgN) | O(lgN) | O(lgN) |
Okay, since we already praised the fact that BST can search for an element in logarithmic time. How does it actually work? Remember that the nodes are distributed in the binary tree with the order key(left child) < key(root) < key(right child), so we know that if we want to find the smallest key we just have to go down to the leftmost node in the tree, finding the largest key in the tree would be the other way around.
BST Search
Since BST is a non-linear data structure, there is no unique way for traversal. There are two common ways to traverse in the tree, both of O(lgN):
- Depth-First Search (DFS)
- Pre-Order
- In-Order
- Post-Order
- Breadth-First Search (BFS)
- Level-Order
Depth-First Search (DFS)
There are three types of depth-first search. They don’t differ in speed or efficiency. They just differ in the order where they visit the nodes.
- Pre-Order Traversal
- In-Order Traversal
- Post-Order Traversal
1. Pre-Order Traversal
Traversing the BST by visiting the parent node first, then its left child, and then its right child.
root -> left child -> right child
void PreOrder(TreeNode *t) {
Visit(t); // visit root.
PreOrder(t->left);
PreOrder(t->right);
}2. In-Order Traversal
Traversing the BST by visiting the left child first, then the parent, and then its right child. Its also the sorted order of visiting the tree.
left child -> root -> right child
void InOrder(TreeNode *t) {
InOrder(t->left);
Visit(t); // visit root.
InOrder(t->right);
}3. Post-Order Traversal
Traversing the BST by visiting the left child first, then the right child, and then the parent.
left child -> right child -> root
void PostOrder(TreeNode *t) {
PostOrder(t->left);
PostOrder(t->right);
Visit(t); //visit root.
}Breadth-First Search (BFS)
There is only one type of breadth-first search, the level order traversal.
- Level-Order Traversal
Level-Order Traversal
Traversing the BST level by level from leftmost to rightmost. Start from the root node at level 0, go to level 1, go through all nodes in level 1 from left to right, go to level 2 and so on.
void LevelOrder(TreeNode* t) {
if (!t) return;
queue<TreeNode*> q;
q.push(t);
while (!q.empty()) {
TreeNode* temp = q.front();
q.pop();
Visit(temp);
if (temp->left)
q.push(temp->left);
if (temp->right)
q.push(temp->right);
}
}BST Insertion
Inserting a node in a BST is straightforward, since we have the ordering property and no duplicate keys are allowed. It is almost identical to searching a node in a BST where you start from the root, recursively go down either in left subtree or right subtree depending on the value of the new key. Once you reach to that location, you link it to its parent either as a left child or a right child. Inserting any node is always at the deepest level of the tree (a new leaf).
BST Deletion
Unlike Insertion, deleting a node might be tricky and less obvious. There are three scenarios to consider when deleting a node in a BST.
- Node to delete has no children (A leaf node)
- Node to delete has one child
- Node to delete has two children
1. Node (N) to delete has no children (A leaf node)
Deleting a leaf node is the simplest case. It doesn’t have children so there won’t be any tree split. Simply delete it.
2. Node (N) to delete has one child
Say we want to delete (N) where its child is (C) and its parent is (P). Deleting (N) will cause a tree split between (P) and (C). So you just need to bypass (N) where you link (C) to (P) as (P)’s new child instead of (N), and then safely delete old (N).
3. Node (N) to delete has two children
This scenario again splits the tree into two sub-trees. There are two solutions for it.
- Find N's Successor (Smallest node in the right sub-tree of N), replace it with N (now N has become a leaf), and then delete N.
- Find N's Predecessor (Largest node in the left sub-tree of N), replace it with N (now N has become a leaf), and then delete N.
Not quite… It is a pretty useful data structure, but what if the nodes weren’t properly distributed in a BST? Imagine you have an array of N elements that is sorted and you build a BST with it. what would the tree look like?
| Operation | Best Case | Average Case | Worst Case |
|---|---|---|---|
| Search | O(lgN) | O(lgN) | O(N) |
| Insert | O(lgN) | O(lgN) | O(N) |
| Delete | O(lgN) | O(lgN) | O(N) |