Hash Tables
Hash Table is a key-value data structure which stores the data in an associative manner. A Hash Table stores the data as key-value pairs where the key is an output of a defined hash function and the value is the data itself that needs to be stored.
The idea of hashing is important in Computer Science. Hashing in general is a function applied to some key where we can determine the position of its value or entry in the array without going through the entire array. We refer to it as a “Hash Function”. Under ideal circumstances, the cost of searching for a key is constant, i.e., O(1).
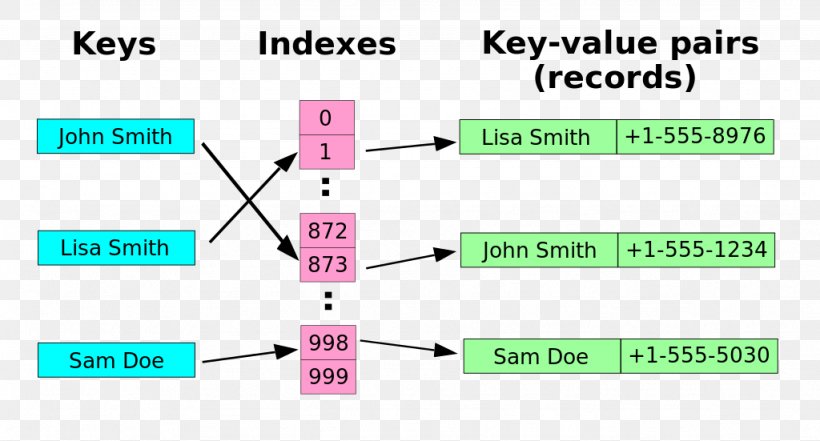
An example of a basic Hash Table
Working with Hash Tables is incredibly important because now we have the ability to perform a set of operations like Search/Add/Delete on a certain record in constant time. This can be used as a lookup dictionary when solving lots of problems, given that the hash function is efficient and can provide that O(1) time complexity. An efficient hash function should provide a unique hashed key for every key.
What if the hash function was poorly written? Meaning that when we hash two keys, we get the same hashed value? That’s where collision happens.
Collision Detection
Collision happens when two keys hash to the same position, say for example we have a table of size 11 and two keys, 55 and 66 and our hash function is key % size.
You will find that
Hash(key=55) = 55 % 11 = 0
Hash(key=66) = 66 % 11 = 0
As you can see, two distinct keys map to the same location which are called “synonyms” and the situation is called “collision”
Methods for handling collisions
- Separate Chaining (Open Hashing): Chaining is a collision resolution mechanism. A smaller table is used in which each location is associated with a linked list. Synonyms of a key in slot are stored in the linked list associated with that slot. Searching is done by hashing the key first to a main slot and if not found, a linear search is conducted in the associated linked list.
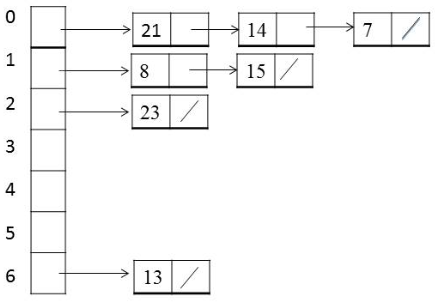
- Open Addressing (Closed Hashing): We use a simple rule to decide where to put a new item when the desired space is already occupied. We always put it in the next occupied cell. On serching for a given item, we go to the intended location and search sequentially. If we find an empty cell before we fine the item, it does not exist anywhere in the table.
- Linear Probing
- Quadric Probing
- Double Hashing
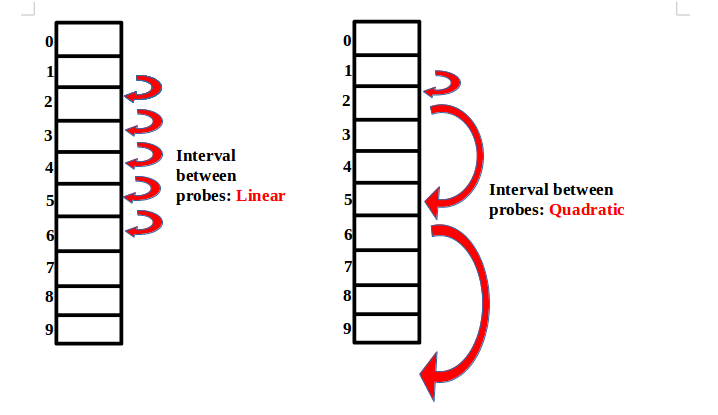
Given a hash table with some inserted entries, we want to determine the performance of that table we use
Load Factor is a metric used to estimate the performance of a hash table. As the load factor grows larger, the hash table becomes slower. A low load factor is not especially beneficial because if the load factor approaches 0, the proportion of unused areas in the hash table increases, but there is not necessarily any reduction in search cost. This results in wasted memory.
Load Factor Formula is α = # of keys / SIZE
// A Basic Class of a HashTable (No Collision Handling)
template <typename KeyType, typename DataType>
class HashTable {
private:
DataType *A;
int size;
int hash(KeyType _key);
bool keyExists(KeyType _key);
public:
HashTable(const int _size);
void Insert(KeyType k, DataType v);
void Delete(KeyType k);
DataType Get(KeyType k);
void DisplayTable();
~HashTable();
};Properties of Hash Functions:
- Hash Functions should be simple and fast.
- Hash Functions should provide a uniform distribution across the table.
- Hash Functions should not cluster keys in regions of the table, using MaxSize as a prime number reduces clustering.
- Hash Functions should provide collisions as minimum as possible.
- Less Load factor without waste in memory.
There is an important concept when it comes to Hash Tables as well called Amortization which I highly recommend reading.